このチュートリアル用のスライド
ATALSでの分散計算環境での解析処理の投入方法(Gridジョブ)
ATLASのユーザー解析ジョブをGridに投入するにはProduction ANd Distributed Analysis (PanDA)というシステムを使います。 Athenaのジョブを投入する場合はpathena、ROOTやその他の一般のジョブを投入する場合はprunというコマンドを使います。 それでは、このpathenaやprunといったPanDAクライアントの使い方を確認していきます。Pathena Hello World ジョブ
Athenaの環境設定から始めましょう。
- $ mkdir -v tutorial2016; cd tutorial2016
- $ setupATLAS
- $ asetup AtlasProduction 20.7.5.1 here
- $ get_files -jo HelloWorldOptions.py
- $ lsetup emi
- $ lsetup panda
- $ pathena HelloWorldOptions.py --outDS user.YourNickname.tutorial2016.12 --noOutput
- $ voms-proxy-info --all | grep nickname
- $ pbook
- INFO : Synchronizing local repository ...
- INFO : Got 1 jobs to be updated
- INFO : Updating JobID=120308 ...
- INFO : Synchronization Completed
- INFO : Done
- Start pBook 0.5.61
- >>> show()
- ======================================
- jediTaskID : 10262517
- taskStatus : done
- JobsetID : 94
- type : panda-client-0.5.72-jedi-athena
- release : Atlas-20.7.5
- cache : AtlasProduction-20.7.5.1
- inDS :
- outDS : user.gkawamur.tutorial2016.12.log/
- creationTime : 2016-12-19 14:49:51
- lastUpdate : 2016-12-19 14:51:43
- params : pathena HelloWorldOptions.py --outDS user.gkawamur.tutorial2016.12 --noOutput
- inputStatus :
- finished : 1
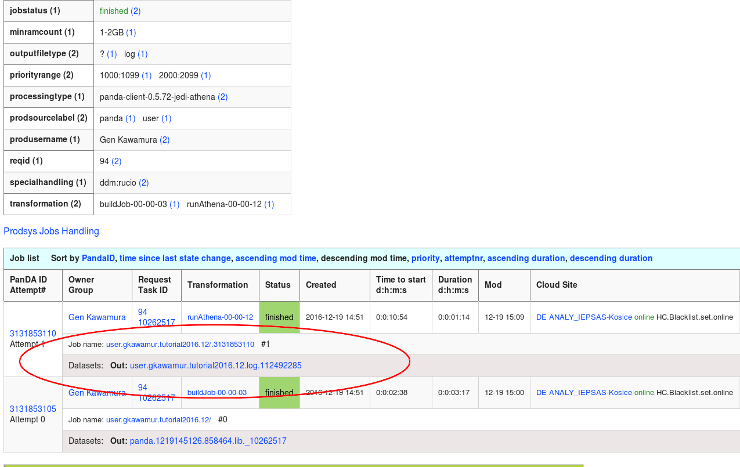
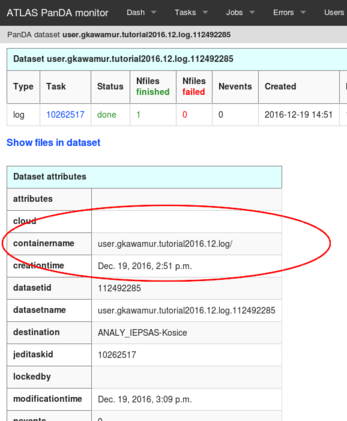
- $ rucio download user.gkawamur.tutorial2016.12.log/
- $ cd user.gkawamur.tutorial2016.12.log
- $ tar zxvf user.gkawamur.tutorial2016.12.log.10262517.000001.log.tgz
- tarball_PandaJob_3131853110_ANALY_IEPSAS-Kosice/
- tarball_PandaJob_3131853110_ANALY_IEPSAS-Kosice/memory_monitor_summary.json
- tarball_PandaJob_3131853110_ANALY_IEPSAS-Kosice/jobState-3131853110.pickle
- tarball_PandaJob_3131853110_ANALY_IEPSAS-Kosice/PoolFileCatalog.xml
- tarball_PandaJob_3131853110_ANALY_IEPSAS-Kosice/athena_stdout.txt
- ...
- $ less tarball_PandaJob_3131853110_ANALY_IEPSAS-Kosice/athena_stdout.txt
- $ athena HelloWorldOptions.py
Pathena テストジョブ
MCイベントジェネレーター まず、athenaで(ローカルマシン上で)動くか見てみましょう。このPythiaジョブオプションファイルをダウンロードしてください。このジョブオプションでは5イベントのみを生成します。
- $ asetup 17.2.4,here,setup
- $ github_repo=https://genkawamura.github.io/2016-ATLAS-Japan-computing-tutorial
- $ wget --no-check-certificate $github_repo/athena_job_options/jobOptions.pythia16.py
- $ athena jobOptions.pythia16.py
- $ lsetup panda
- $ pathena jobOptions.pythia16.py --outDS user.YourNickname.evgen.pool.pythia.v1 --split 5
- $ pathena HelloWorldOptions.py --outDS user.YourNickname.tutorial2016.12 --noOutput --destSE TOKYO-LCG2_LOCALGROUPDISK
prun Hello World ジョブ
次は、prunによりHello Worldジョブを投入してみます。まずは、簡単なスクリプトでテストしてみましょう。
- $ mkdir grid; cd grid
- $ echo -e "hostname > test.out\nprintenv >> test.out" > test.sh
- $ chmod +x test.sh
- $ lsetup panda
- $ prun --exec "test.sh" --outDS user.YourNickname.tutorial2016.12.prun_hello_world --outputs test.out
- $ rucio download user.gkawamur.tutorial2016.12.prun_hello_world_test.out/
- $ cat user.gkawamur.tutorial2016.12.prun_hello_world_test.out/user.gkawamur.7939538._000001.test.out
prun PyRoot xAOD 解析ジョブ
ここでは、より実用的にPyRootを使用してxAODファイルを読み込みグリッドで処理します。PyRootはROOTのライブラリをPythonで使用することができるラッパーですが、単純な処理の場合には非常に簡潔にコードを書くことができるので時間を節約することができます。 環境設定 後々のことも考えて(環境設定やデータの準備などの)基本的な処理をShellスクリプトにまとめておきます。 PyRootを実行するにはRootCoreが必要になります。またデータ準備のためにRucioの環境設定、ジョブサブミッションのためにPanDAクライアントの環境設定が必要です。毎回入力するのは面倒なので、pyroot_env.shという環境設定スクリプトを書いておきます。pyroot_env.shの内容はCVMFSの環境設定を羅列しただけです。
setupATLAS rcSetup Base,2.0.2 rc find_packages rc compile lsetup rucio lsetup pandaPyRootグリッド環境を設定するには、以下のように呼び出します。
- $ source pyroot_env.sh
- $ ./rucio-get-files.sh [options]
- -d: dataset [default: valid2.117050.PowhegPythia_P2011C_ttbar.digit.AOD.e2657_s1933_s1964_r5534]
- -n: number of files [default: 1]
#!/usr/bin/env python
# based on an example here: https://twiki.cern.ch/twiki/bin/view/AtlasComputing/SoftwareTutorialxAODEDM#PyROOT_with_the_xAOD
import sys, os, time, glob, re
import getopt
import ROOT
def main(argv):
# parsing command arguments
inputfile='input.txt'
outputfile='hist.root'
try:
opts, args = getopt.getopt(argv,"hi:o:",["ifile=","ofile="])
except getopt.GetoptError:
print 'xAOD_electron_hist_example.py -i [inputfile] -o [outputfile]'
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print 'xAOD_electron_hist_example.py -i [inputfile] -o [outputfile]'
sys.exit()
elif opt in ("-i", "--input"):
inputfile = arg
elif opt in ("-o", "--output"):
outputfile = arg
print 'Input file is', inputfile
print 'Output file is', outputfile
# Set up ROOT and RootCore:
ROOT.gROOT.Macro( '$ROOTCOREDIR/scripts/load_packages.C' )
# Initialize the xAOD infrastructure:
ROOT.xAOD.Init()
# a histogram for our output
outfile=ROOT.TFile.Open(outputfile,"RECREATE")
pthist=ROOT.TH1F("pt","pt;p_{T} [GeV];Entries / 10 GeV",100,0,1000)
treeName = "CollectionTree" # default when making transient tree anyway
# Loop on the input files. There are surely ways to chain the trees together,
# which is left as an exercise to the reader.
for i in ([file for file in open(inputfile).read().strip().split(',')]):
print "Opening file "+i
f = ROOT.TFile.Open(i)
if not f:
print "Couldn't open input file "+i+"... will not continue."
sys.exit(1)
pass
# Make the "transient tree":
t = ROOT.xAOD.MakeTransientTree( f, treeName)
# Print some information:
print( "Number of input events: %s" % t.GetEntries() )
for entry in xrange( t.GetEntries() ):
t.GetEntry( entry )
print( "Processing run #%i, event #%i" % ( t.EventInfo.runNumber(), t.EventInfo.eventNumber() ) )
print( "Number of electrons: %i" % len( t.ElectronCollection ) )
# loop over electron collection
for el in t.ElectronCollection:
pthist.Fill(el.pt()/1000.)
pass # end for loop over electron collection
pass # end loop over entries
f.Close()
pass
outfile.cd()
pthist.Write()
outfile.Close()
sys.exit(0)
if __name__ == "__main__":
main(sys.argv[1:])
ではファイルを用意します。
- $ mkdir -v my_lovely_grid_pyroot; cd my_lovely_grid_pyroot
- $ github_repo=https://genkawamura.github.io/2016-ATLAS-Japan-computing-tutorial
- $ wget --no-check-certificate $github_repo/pyroot/pyroot_env.sh
- $ wget --no-check-certificate $github_repo/pyroot/rucio-get-files.sh
- $ wget --no-check-certificate $github_repo/pyroot/xAOD_electron_hist_example.py
- $ chmod +x rucio-get-files.sh xAOD_electron_hist_example.py
- $ source pyroot_env.sh
- $ ./rucio-get-files.sh -n 1
- $ ls valid2.117050.PowhegPythia_P2011C_ttbar.digit.AOD.e2657_s1933_s1964_r5534/* > input.txt
- $ ./xAOD_electron_hist_example.py -i input.txt -o hist.root
- $ ls valid2.117050.PowhegPythia_P2011C_ttbar.digit.AOD.e2657_s1933_s1964_r5534/* > input.txt
- $ root hist.root
- root [1] TBrowser t
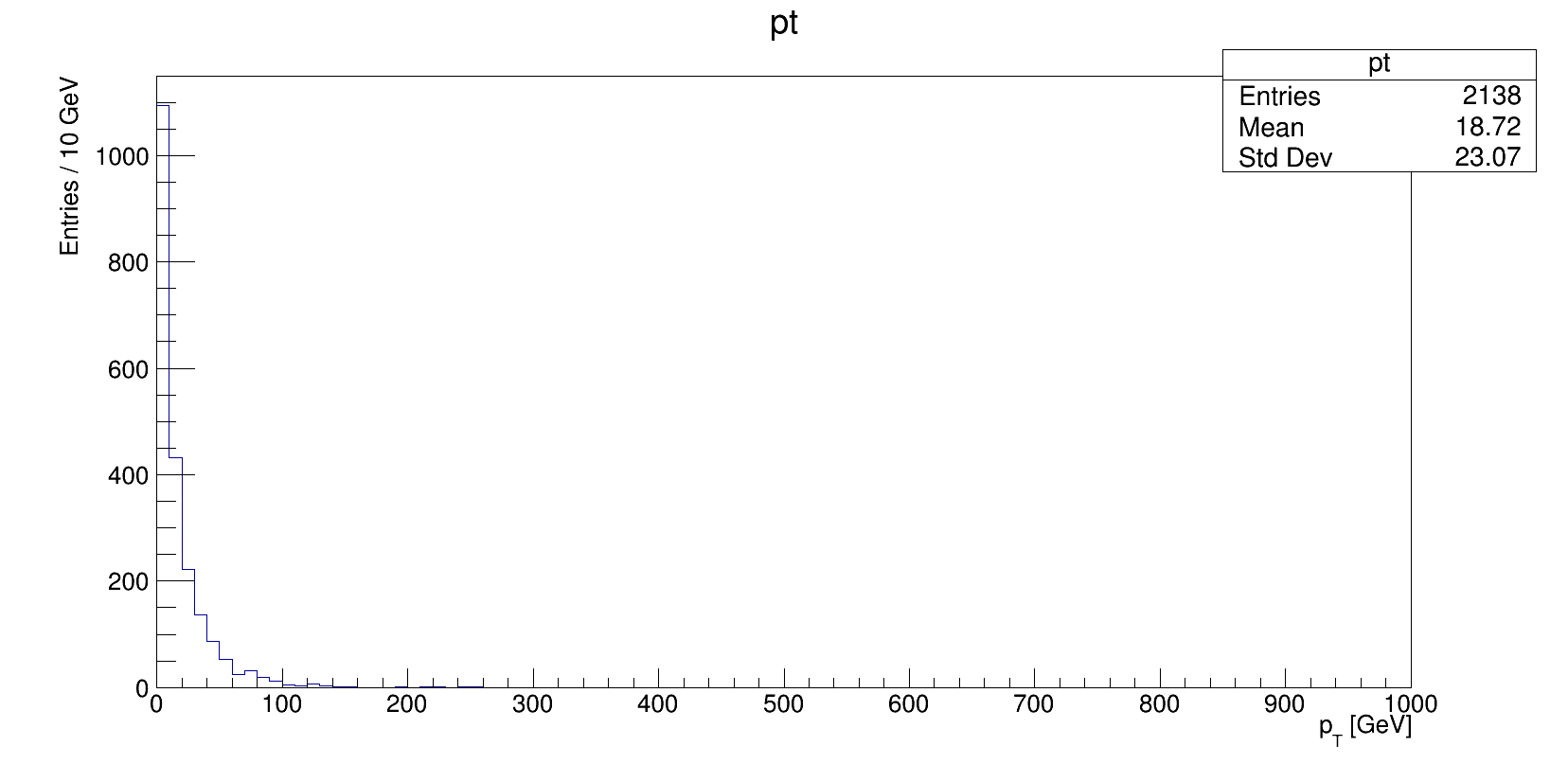
- $ prun --useRootCore --inDS=... --exec "echo %IN > input.txt; xAOD_electron_hist_example.py -i input.txt -o hist.root"
- $ nickname="YourNickname"
- $ inDS="valid2.117050.PowhegPythia_P2011C_ttbar.digit.AOD.e2657_s1933_s1964_r5534"
- $ outDS="user.${nickname}.tutorial.pyroot.xAOD.v0.1_$$"
- $ infile="input.txt"
- $ outfile="hist.root"
- $ prun --useRootCore --inDS=$inDS --forceStaged --outDS=$outDS --outputs=$outfile --nFiles=100 --nFilesPerJob=1 --exec="echo %IN > $infile; xAOD_electron_hist_example.py -i $infile -o $outfile"
- $ rucio download user.gkawamur.tutorial.pyroot.xAOD.v0.1_30934_hist.root/
- $ root user.gkawamur.tutorial.pyroot.xAOD.v0.1_30934_hist.root/user.gkawamur.10325809._000001.hist.root
- root [1] TBrowser t
参考文献、リンク等
ATLASソフトウェア講習会2016.01 ジョブ管理 Twiki - The PanDA Production and Distributed Analysis System Twiki - How to submit Athena jobs to Panda Twiki - Software tutorial Twiki - Derived xAODs Analyzing xAOD in CINT and PyROOT ATLAS-D meeting 2016 Grid/Rucio Tutorial, Gen Kawamura Monitoring Your Grid Jobs, Andrew Washbrook University of Edinburgh, ATLAS Software & Computing Tutorials 14th January 2015 PUC, Chile Software tutorial using Grid ATLAS Software Tutorial, Feb 2016 Calafiura, Paolo, et al. "The ATLAS Event Service: A new approach to event processing." Journal of Physics: Conference Series. Vol. 664. No. 6. IOP Publishing, 2015.